
Follow the Five Percent: What Graph-Literate Enterprises Did Differently and Why It Matters
The 5% will connect their data, empower their staff, and own their intelligence.
The 5% are not smarter. They are not better funded. They simply noticed, at some point, that the world is made of relationships, and built their systems to remember that. The other 95% are still extracting it into rows, one cell at a time, and wondering why the model cannot tell them anything they did not already know.
Follow the Five Percent.
Abstract
Follow the Five Percent. That is the prescription.
Ninety-five percent of enterprise AI pilots fail. The 5% who succeed are public companies, filing audited results, documenting their architectures, growing 30% year on year. This paper examines what that 5% actually did. The answer is the same in every case: they kept the connections in their data alive. Lemonade processes claims in 2 seconds across 18 fraud-detection algorithms because the chain from customer to policy to claim to fraud signal to payment is one connected walk. Root Insurance prices motor policies from live telematics feeds and grew to $1.52 billion in revenue because the driver is connected to the driving. Allianz automates food-spoilage claims during storm events in under 5 minutes. AXA Switzerland achieves greater than 99% accuracy in automated claims triage. None of them necessarily runs a 'knowledge graph.' All of them treat relationships between entities as first-class objects that AI can traverse and reason over. McKinsey's analysis shows AI-leading insurers generating 6.1 times the total shareholder return of laggards over five years. The AI in insurance market is projected to reach $175-303 billion by 2035 depending on analyst methodology. The pattern extends beyond insurance: the 2008 financial crisis, healthcare adverse events, intelligence failures, and COVID-19 transmission models all exhibited the same structural blindness - data that had been disconnected from its relational context. Fix the shape and the AI starts working. Keep the shape and no amount of spending will change the outcome. The blueprint is public. The results are audited. Follow the Five Percent.
Keywords: knowledge graphs, enterprise AI success, insurance technology, graph literacy, connected data, data architecture, relational reasoning
1. Follow the Five Percent
Ninety-five percent of generative AI pilots at companies fail before reaching production [1]. The other 95% are, presumably, still in a Slack channel called #ai-taskforce-v3-FINAL, waiting for someone to find the password to the staging environment. More than 80% of enterprise AI projects never make it to deployment - roughly double the failure rate of traditional IT projects [2]. These numbers are not disputed. MIT reported them. RAND confirmed them. McKinsey measured them.
The usual response is to commission a post-mortem. Someone writes a report. The report says data quality, or talent, or executive alignment [3]. Everyone nods. The next pilot fails for the same reasons. Another report is commissioned. It reaches broadly the same conclusions. This has been going on for some time now.
This paper skips the post-mortem and asks a simpler question.
The 5% who succeed are right there. In public. Filing annual reports with the SEC. Publishing investor presentations with specific performance metrics. Growing 30% year on year while the rest of the industry spends millions on pilots that never ship. They are not operating in stealth. They are listed on stock exchanges.
So why doesn't anyone just copy them?
Not their code. Not their vendor. Not their AI model. Their approach - the one structural decision that separates the 5% from the 95%. It is not hidden. It is not complicated. Once someone points it out, it is almost embarrassingly obvious.
They kept the connections in their data alive.
Every claim in what follows is sourced from public filings, peer-reviewed research, or audited financial results.
2. What the Winners Actually Did
2.1 Lemonade: The Two-Second Claim
A customer files a claim. Lemonade's AI agent - they call it AI Jim - does the following:
- Reads the claim
- Checks the customer's policy
- Checks the customer's claim history
- Checks the claimant against 18 different fraud detection algorithms
- Cross-references third-party data
- Approves the payout
- Sends the money
That takes two seconds. One claim. Eighteen checks. No human touched it.
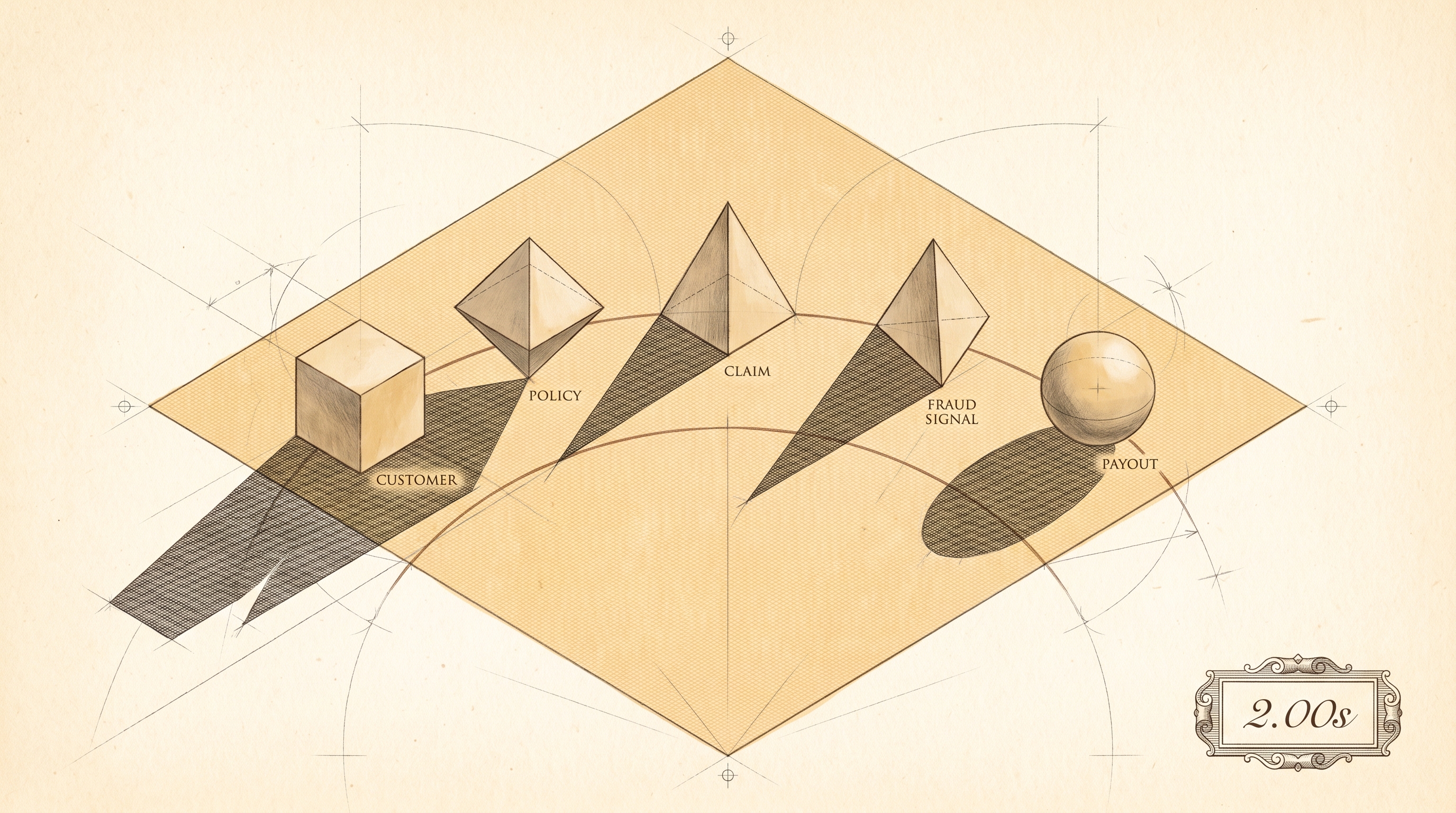
It works because every piece of information AI Jim needs is already connected. Customer to policy to claim to fraud signal to payment method to history. One continuous chain. The AI walks along the chain and makes a decision at the end of it.
Now picture the same claim at a typical UK insurer. The claim arrives in one system. The policy lives in another. The fraud rules sit in a third. Someone exports a spreadsheet from each, pastes them into a fourth, and sends the result to a handler who reads it on Tuesday. The handler queries a fifth system to check the claim history, waits for an overnight data refresh, and makes a decision on Thursday. If everything goes smoothly - and the handler does not go on holiday, and the fifth system does not time out, and nobody has changed the column headers since last quarter - settlement happens in 25 to 30 days.
Same claim. Same industry. One takes two seconds. The other takes the better part of a month.
The financial results bear this out. Q2 gross loss ratio improved from 79% in 2024 to 67% in 2025 - a 12-point year-on-year improvement during a period of aggressive AI deployment over connected data architecture. Revenue up 35% year-on-year. Approaching 3 million policyholders. $1.083 billion in-force premium [20].
2.2 Root Insurance: The Living Price
Most insurers price a motor policy like this: once a year, an actuary pulls last year's claims data, runs a regression, and produces a rate table. That table sits in a spreadsheet. It gets uploaded to the pricing engine. For the next twelve months, every customer is priced from a snapshot of a world that has moved on without them.
Root does something that sounds unremarkable until you think about what it implies. If you drive a Toyota or Lexus, your car sends driving data directly to Root's pricing model through the manufacturer's API. Not once a year. Continuously. The connection between you, your car, how you drive, where you drive, and when you drive is live. The price reflects reality, not last year's memory of it.
Root grew to $1.52 billion in revenue in 2025. Up 29% in a year. Net income $40.3 million. The fastest-growing US auto insurer above $1 billion in premium. Telematics opt-in rates in the high-80% range - industry-leading by a wide margin [21].
They did not build a better regression. They connected the driver to the driving.
2.3 Allianz Australia - Project Nemo: Storm Claims in Five Minutes
A storm hits. Hundreds of food spoilage claims come in at once. Most insurers would put the kettle on and start working through the queue. Allianz Australia deployed a chain of specialised AI agents that divide the work between them - reading the claim, checking policy coverage, verifying the storm actually happened in that location, estimating the loss, checking for duplicates, flagging anything suspicious, and approving the payout.
Analysis complete in under 5 minutes from filing. Processing time cut by 80% [23].
Each agent can do its job because it can see the connections between the claim, the weather event, the location, the policy, and the claimant's history. Those connections are there by design. At the typical insurer, those same facts are scattered across six spreadsheets maintained by three different departments who update them on different schedules, use different definitions of "customer," and communicate primarily through the medium of slightly passive-aggressive emails about data discrepancies. Analysis complete in under 5 minutes at Allianz. Analysis complete in under 5 weeks at the typical insurer, if the spreadsheets agree on what a customer is.
2.4 Shift Technology at AXA Switzerland
Shift Technology built an AI that scores incoming claims by complexity and decides which ones a human needs to see and which ones can be automated. At AXA Switzerland: 3% lower claims losses, 30% faster handling, 60% automation rate, greater than 99% accuracy [22].
The system works because it reasons across the full chain - claimant to incident to vehicle to repair shop to historical pattern to fraud indicator. It does not look at one row in one table. It looks at the whole neighbourhood of connections around a claim and decides whether the picture makes sense. Remarkably often, it does.
3. The Pattern
Four companies. Four different tech stacks. Four different markets. Four different cloud providers. Four different AI models.
One thing in common: they all kept the connections in their data alive.
Customer connects to policy. Policy connects to claim. Claim connects to fraud signal. Signal connects to history. History connects to renewal. The chain is unbroken. The AI can walk along it and reason.
A clarification is worth making here. None of these companies necessarily operates a labelled 'knowledge graph' or 'graph database' in production. What distinguishes them is architectural: their systems treat relationships between entities - driver to vehicle to context to claim to fraud indicator - as first-class objects with their own properties and inferential weight. Whether the underlying storage is graph-native or relationally modelled with rich semantic layers is secondary. The relevant variable is whether the architecture permits multi-hop relational reasoning or forces it through the bottleneck of tabular joins and overnight batch processes.
That is the entire secret of the 5%. Not better AI. Not more data scientists. Not bigger budgets. Connected data. You could fit the insight on the back of a napkin and still have room for a diagram.
Which rather raises the question of why the other 95% cannot see something this obvious. The answer, unfortunately, is that they have been carefully taught not to.

4. Why Most Organisations Cannot See This
4.1 The Data Shape They Were Given
The tabular or relational model assumes that entities possess fixed attributes, that relationships between entities are secondary to the entities themselves, and that the world operates within a closed schema [5]. This structure has dominated enterprise computing since Codd's relational model in 1970 and its commercial implementation through SQL databases, spreadsheets, and ERP systems.
This dominance was earned. Codd's relational algebra solved genuine problems that no prior paradigm had addressed: ACID transactions guaranteed data integrity under concurrent access. SQL provided a standardised query language that dramatically lowered the barrier to data retrieval. Normalised schemas offered regulatory legibility - an auditor could inspect a table and verify compliance without understanding the business domain [5].
Tables are not the enemy. A general ledger should be a table. A regulatory return should be a table. High-volume aggregation and transactional recording are precisely the problems that relational databases were built to solve, and they solve them well.
The problem is not the table. It is using only tables and assuming that every domain question can be answered within their constraints. Every spreadsheet declares: "This entity has exactly these attributes and no others." Every column declares: "This dimension of reality is fixed and universal." Every missing join quietly declares: "These things are not related" - when often the relationship is the most important fact in the room.
The tabular shape forbids the recognition of emergent properties, multi-membership, context-dependent identity, and the premise that relationships might be the primary carriers of meaning [6]. It was designed to make complex reality administratively legible - reportable, auditable, and controllable [7]. An excellent thing for a table to do. A peculiar thing to build your entire intelligence strategy on.
4.2 The Graph Shape the Winners Use
The graph or network shape assumes that entities are fundamentally defined by their relationships, that structure is emergent rather than imposed, and that meaning is entirely contextual [8]. Graph structures permit multi-hop inference, dynamic membership, polyphonic categorisation, and the treatment of relationships as first-class objects with their own properties and histories.
This is not exotic technology. It is how human cognition naturally works. Developmental psychology shows that infants spontaneously extract relational patterns ("same" vs. "different") from around seven months of age [9]. Social cognition - the ability to track who knows whom, who trusts whom, who is likely to defect - is the primary driver of primate brain expansion [10]. Systems thinking, as described by Donella Meadows, identifies feedback loops, stocks, and flows as the essential graph structures that govern complex behaviour [11].
The table is the anomaly. The graph is the default. A seven-month-old baby thinks in graphs.
4.3 Why IT Departments Reproduce the Problem
Standard data science and computer science curricula treat graph theory as a niche elective rather than a core data modelling paradigm. Of thirty university programmes surveyed, fewer than one in six offered a graph database module. Formal knowledge representation training was rarer still [15]. No comprehensive academic audit of this curriculum gap yet exists, which tells you roughly how seriously the academy takes it.
These graduates then arrive at their first enterprise job and are tasked with building data substrates for a multi-million-pound AI deployment. They build the only shape they know. Not because they considered the alternatives and rejected them, but because no alternative was ever mentioned in the three years of lectures they sat through [3]. It is as if an entire profession of librarians had been trained to shelve books alphabetically by title, and when someone suggested perhaps arranging them by subject - or, heaven forbid, by the connections between them - the librarians politely explained that alphabetical order had been standard practice since the late 1980s and saw no reason to revisit it. Ralph Kimball's dimensional model - the conceptual scaffolding of nearly every enterprise warehouse since 1996 - has been pronounced dead so many times it must be feeling like a Hammer Horror villain. And yet the columns persist, the joins multiply, and the relationships keep dying quietly inside them.
Dimensional modelling assumes the world arrives pre-sliced into facts and dimensions, like a sushi tray. The world, regrettably, does not.
The monoculture is then actively reinforced by the institutions that hired them. Procurement frameworks demand relational architectures because of existing legacy licences. Database administrator guilds protect their domain expertise with the quiet ferocity of medieval craft unions. Enterprise tooling - Power BI, Tableau, every ERP reporting layer on the market - is designed to consume tabular data and has no native capacity for graph traversal [16]. The graduate who wanted to try something different would need to fight procurement, the DBA guild, the tooling stack, and their own training, simultaneously, on their first week.
Philip Tetlock's research on forecasting distinguishes between "hedgehogs" (who know one big thing and apply it everywhere) and "foxes" (who know many things and integrate across domains) [18]. An organisation committed to a single data paradigm exhibits the same cognitive disposition as the hedgehog forecaster - it interprets every domain through the one framework it trusts, even when the domain is visibly resisting. The SQL monoculture is institutional hedgehoggery. It carries the same forecasting penalty that Tetlock documented in individuals: the hedgehog is confident, articulate, and wrong more often than a dartboard.
The 5% broke the monoculture. Not by abandoning tables - they still use them for what tables are good at. They broke it by adding a second shape: a connected layer that lets AI see relationships, not just rows.
4.4 The Evidence from the Data
As schema complexity increases, text-to-SQL accuracy degrades sharply - a well-documented pattern across benchmarks including BIRD-Bench and Spider 2.0, where complex multi-join queries routinely defeat the majority of AI agents tested [12]. What this means in practice is that the AI, eager to please, scans the database schemas, notices that the home claim table and the pet policy table both happen to have a column labelled "ID," assumes they are the same thing, executes a join, and happily concludes that the spaniel caused the flood because both events occurred on a Tuesday and share the integer 42. It is articulate, confident, and fundamentally wrong. It has no conceptual framework to understand why a dog cannot be a weather event.
Language model accuracy on complex business questions improves from roughly 16% to 54% when grounded in a semantic knowledge graph - a threefold increase in precision [13]. Microsoft's GraphRAG implementation significantly outperforms baseline retrieval-augmented generation on narrative and relational data [14]. Separately, a Forrester Total Economic Impact study of Stardog's enterprise knowledge graph platform found 320% ROI over three years; a separate Forrester study of Neo4j found 417% [14b].
These are not marginal improvements.
5. What the 95% Actually Look Like
Here is a scenario that plays out in almost every UK insurer, every day. Nobody writes it down because nobody considers it remarkable.
A customer has a motor policy. Her husband is on the same policy as a named driver. She also has a pet policy with the same company. Last year she made a water damage claim on her home insurance. Her house is 200 metres from a flood plain. Her motor renewal is in six weeks.
The question an AI should be able to answer: "What is the total household exposure, and what renewal bundle makes sense?"
In a connected system, that is one question. The AI sees the customer, the spouse, the motor policy, the pet policy, the home policy, the prior claim, the flood risk, and the renewal date. All one picture. The answer takes milliseconds.
In a typical UK insurer, those facts live in five different systems:
- Motor policy in CDL Strata
- Named drivers in a separate module
- Pet policy in a different product platform entirely
- Home claim in Guidewire ClaimCenter
- Flood data in an external feed that gets refreshed quarterly
Nobody joins them. Nobody has been asked to. These five systems sit in the same building, process the same customer's money, and have absolutely no idea the others exist. They are like obstinate goats tied to separate posts in the same field, each facing a different direction, each entirely convinced that their post is the only post. The AI never sees the picture. It cannot find the husband. It does not know about the flood plain. It cannot connect the water damage claim to the home location to the flood risk to the renewal date. It has never occurred to the systems that these facts might be related, because nobody built them to think that way.
So the renewal goes out at the standard rate. No bundle. No flood risk adjustment. No cross-sell. The customer gets a better offer from a competitor and leaves. The insurer loses the household.
Multiply that by a million customers and you have the 95%.
The connections were thrown away before the AI ever saw the data. Not deliberately. They simply did not fit the shape. A spreadsheet has no column for "is married to" or "lives near a flood plain" or "made a claim on a different product last year."
The goats remain tethered to their separate posts, staring in their separate directions with the quiet dignity of systems that have never been told they are part of the same herd. And if they were merely losing revenue, one might be tempted to leave them to it. But they are about to cause something considerably worse than a missed cross-sell. They are about to collide with the law.
6. The Pattern Repeats Beyond Insurance
Insurance is the primary case study because it is an almost pure graph problem - policies, claims, fraud rings, and cross-sell opportunities are all relationship chains. But the pattern of connected-data winners and disconnected-data losers shows up well beyond insurance.
Financial services: The 2008 financial crisis was multi-causal - regulatory capture, ratings agency conflicts, moral hazard, and excessive leverage all played critical roles [27]. But among the contributing factors was a representational failure. Collateralised Debt Obligations were individually rated as low-risk based on attribute-level (tabular) analysis. The correlation structure - the graph of underlying exposure dependencies - was invisible in the ratings models. 79% of all BBB-rated subprime bonds were placed or referenced in synthetic CDOs, creating a highly correlated system that no tabular risk model could detect [27]. Each row looked fine. The connections between them did not.
Healthcare: Clinical adverse events frequently stem from drug interaction and contraindication failures where the knowledge exists in the literature but remains disconnected across tabular patient records rather than connected in a knowledge graph of drug-mechanism-patient relationships [28]. The information is there. It is in five different systems that do not talk to each other. One begins to notice a theme.
Intelligence: The 9/11 Commission documented failures that were primarily governance and legal [29]. But even within agencies, relevant signals were stored in disconnected databases. Different agencies held different rows about the same network. The connections existed in reality but not in any system. Nobody could walk the chain because there was no chain to walk.
Epidemiology: COVID-19 transmission models that assumed well-mixed (tabular) populations systematically underestimated transmission. The dispersion parameter k was 0.1-0.2, meaning 10-20% of infected individuals caused 80% of new infections - a graph property invisible to models that did not model network structure [30].
In every case, the institutions that got the response right were the ones that could see the connections.
7. The Money on the Table
McKinsey's analysis found that a small cohort of AI-leading insurers has created 6.1 times the total shareholder return of AI laggards over five years - a wider gap than in most other sectors [24].
It is worth pausing on that number. Not 6.1 percent. Six times. If your competitor is in the 5% and you are in the 95%, they are not slightly ahead. They are in a different race.
McKinsey attributes this gap to depth of AI integration across the operating model - talent, governance, and workflow redesign [24]. This paper does not dispute that attribution. It argues that effective AI integration requires a data substrate capable of supporting relational reasoning, and that tabular-only architectures place a structural ceiling on the depth of integration achievable. You can have the best AI talent in the building, but if the data has been pre-flattened into disconnected spreadsheets, the talent has nothing connected to work with.
A note of honesty is required. Connected architecture does not guarantee success. The insurtech landscape includes instructive failures. Metromile, a telematics-native insurer, was acquired by Lemonade in 2022 after failing to achieve sustainable scale. Hippo suffered significant market write-downs. Root itself traded below its IPO price for years before achieving profitability in 2025. Digital-native architecture was a necessary precondition for their AI capabilities, not a sufficient condition for commercial success. Capital discipline, actuarial competence, regulatory navigation, and market timing were all required alongside it. You can have a graph and still fail. You cannot succeed without one.
The AI in insurance market, approximately $15 billion today, is projected to reach $175-303 billion by 2035 depending on analyst methodology [25]. McKinsey estimates generative AI alone could unlock $50-70 billion in insurance revenue [24]. $50 to $70 billion. A range so wide it contains the entire GDP of Luxembourg twice over, and yet board members will nod at it as if someone had just quoted the temperature. Deloitte projects P&C insurers could save up to $160 billion by 2032 through AI-driven fraud analytics alone [26].
That money will go somewhere. The only question is whose AI can reason about their business when it arrives.
8. Who Actually Pays
Before we discuss the technology any further, it is worth remembering who actually pays for all of this.
Not the board. Not the CIO. Not the AI vendor. The customer pays. The policyholder whose premium rises 20% because the algorithm correlated her postcode with a risk profile it could not contextualise. The claimant whose valid claim is denied because the AI could not see the connection between the water damage and the flood plain 200 metres from her house. The patient whose adverse drug reaction was entirely predictable from information that existed in three separate NHS systems, none of which had been introduced to the others.
The Consumer Duty exists because the financial services industry has a documented history of delivering outcomes to customers that the customers themselves would not choose if they understood what was happening. The FCA's mandate is unambiguous: fair value, clear understanding, demonstrably good outcomes. When an AI makes a decision that affects a human being's finances, health, or safety, someone must be able to explain why.
In the NHS, the stakes are not financial. They are mortal. Clinical adverse events frequently stem from drug interaction failures where the knowledge exists in the literature but remains disconnected across separate patient record systems [28]. A connected patient graph does not merely improve efficiency metrics. It catches the contraindication before the prescription is written. It flags the allergy before the anaesthetic is administered. It connects the presenting symptoms to the family history that sits in a different trust's database. Fragmented patient data is not an IT inconvenience. It is a source of preventable suffering and preventable death.
When a hyper-intelligent AI collides with these realities, the results are spectacularly messy.
Picture the scene. The AI, starved of context because the motor policy and the home claim are not speaking to one another, denies a perfectly valid claim. It is not being malicious. It is simply operating in a state of induced corporate amnesia. But the Consumer Duty does not care about your database architecture.
When the regulator comes knocking, demanding to know why the AI made this decision, the executives freeze. You cannot explain a decision made by an algorithm that was fed fragmented noise. A tabular database can tell you what happened - the premium went up by 20%. It cannot tell an auditor why the AI made that choice. If the algorithm quietly correlated a postcode with a risk profile while lacking the connected context of the customer's actual circumstances, you have not built a pricing model. You have built a discrimination engine with a compliance gap where its conscience should be.
The EU AI Act's Article 15 now mandates that high-risk AI systems maintain continuous, auditable accuracy metrics with full data lineage - you must prove how the data travelled from source to transformation to output. The FCA's own fines have recently reached GBP 176 million - a 230% increase - with 75% citing failures in the management and control of data [38]. A graph traversal is an audit trail. Every hop is named, every relationship has provenance. A spreadsheet is not an audit trail. It is a confession that you did not know what your AI was doing.
Panic ensues. And in the grand tradition of British bureaucracy facing a crisis, the executives do what they always do: they throw a staggering amount of money at an external American tech company.
The NHS provides an instructive example. Faced with deeply fragmented patient data - the same fragmentation that contributes to the adverse events described above - the government awarded a GBP 330 million contract to Palantir to build a "Federated Data Platform" [34]. Seven-year term. Subscription model. No software transfers to the NHS when the contract ends. Not a single line of code stays behind. All the bespoke integration work belongs to the supplier [35].
The total cost, with consulting add-ons, is projected to exceed GBP 1 billion. KPMG was paid GBP 8-8.5 million simply to promote adoption among NHS trusts [35]. Individual trusts then report additional local integration costs of GBP 412,000-500,000 each, on top of the central contract [35].
By mid-2025, fewer than one in three of the NHS's 215+ hospital trusts were actively using the platform [35].
GBP 1 billion. No IP transfer. Two-thirds declining to adopt. The patients whose connected data might have caught the contraindication, flagged the allergy, linked the family history across trusts - they are still waiting.
The insurance sector exhibits the same pattern. 61% of AI consulting engagements result in vendor lock-in within eighteen months. Switching costs run GBP 150,000-500,000 per mid-sized project [36]. Global spending on generative AI consulting exceeded $3.75 billion in 2024. Most of those transformations deliver limited lasting value once the external team catches its flight home [36].
8.1 The Scandal of Renting Intelligence
The great scandal of the current AI boom - the bubble that is waiting to be burst - is the illusion that you must pay billions to external black-box vendors to understand your own business. You do not.
BCG's widely cited 10/20/70 framework provides the empirical anchor: AI success is 10% algorithms, 20% technology and data, and 70% people and processes [37]. Organisations that follow this ratio scale successfully. Those that lead with technology and consulting - the 95% - fail precisely because they invert it.
Instead of writing blank cheques to build proprietary systems that your staff cannot navigate, imagine investing in your own people. The NHS and the insurance industry are brimming with brilliant, under-utilised domain experts - clinicians, underwriters, claims handlers - who know the intimate reality of the business better than any external consultant ever could.
All they need is to be taught the true shape of the data.
There is a harder truth here that nobody in the industry is saying out loud. AI will automate a significant proportion of the roles currently performed by claims handlers, underwriting assistants, data entry clerks, and junior analysts. That is not a prediction. It is already happening. The question is not whether those roles change. It is whether the people in them are given a fighting chance.
An underwriter who has spent twenty years learning the intimate logic of risk assessment knows things about the business that no external consultant will ever absorb in a six-month engagement. She knows that "column status four" in the legacy billing system actually means the customer called in angry on a Thursday in 2014 and has been handled with kid gloves ever since. That knowledge is priceless - but only if it can be expressed in a form the AI can use. Teach that underwriter to map their expertise as a business ontology - to draw the relationships between risk factors, policy structures, and claim patterns that they carry in their heads - and you have not replaced them. You have promoted them. They become the architects of the intelligence layer, not its casualties.
The alternative is the one currently being practised by the 95%: pay a vendor to build a black box, make the existing staff redundant because the black box is supposed to replace them, and then discover that the black box does not actually understand the business because nobody who understood the business was involved in building it. The AI fails. The expertise has left the building. The vendor sends another invoice.
By upskilling existing staff in graph literacy and teaching them how to build their own business ontologies using open, sovereign standards, an organisation does three things at once. It bridges the gap between business reality and data architecture. It satisfies the Consumer Duty because every logical hop the AI makes is traceable, named, and governed by the very people who understand the rules. And it treats its workforce with the basic dignity of giving them transferable skills for the economy that is coming, rather than a P45 and a reference.
The 5% of companies succeeding with AI are not doing it by outsourcing their brains. They are doing it by cultivating their own connected gardens.
9. How to Start: The Semantic Overlay
The good news - and it is genuinely good news - is that following the 5% does not require ripping out existing systems. Nobody needs to phone the CIO on a Friday afternoon and explain that the database is being replaced.
Remember the obstinate goats? They are still there, tethered to their separate posts, facing their separate directions with the institutional serenity of systems that have been doing things this way since 1989. The posts are not going anywhere. Nobody is going to untie the goats and herd them into a single magnificent super-paddock. That would cost a fortune, take three years, and the goats would refuse to cooperate.
Instead, what you need is a very patient, slightly overworked shepherd. The shepherd does not move the posts. He does not relocate the goats. He simply draws a map in the dirt between them. "This goat over here," the shepherd explains, "is actually the same customer as that goat over there. And that goat by the fence is standing in a flood plain, which is rather relevant to the goat with the water damage claim." Then the shepherd walks over and gently turns the motor policy goat's head, so it can finally see the home claim goat grazing 200 metres away.
That is all a semantic overlay does. It maps the connections between your existing systems without moving anything. Nothing breaks. Nothing migrates. Your existing databases keep doing what they do. But now the AI can see the relationships between them, because someone finally drew the lines in the dirt.
Virtual knowledge graph platforms enable this graph-aware querying over relational backends, releasing early value before a single table is migrated. CIOs approve it because nothing changes in production. CFOs approve it because ROI arrives in months, not years. And for compliance officers: every hop the AI takes across the graph is traceable, every relationship is named, every inference has provenance. The audit trail writes itself.
9.0 What It Actually Costs
A semantic overlay pilot - one domain, one set of connections drawn in the dirt - costs GBP 200,000-400,000. A mid-sized enterprise rollout runs GBP 500,000-2 million. Even a large-scale deployment across an organisation the size of the NHS or a global insurer sits at GBP 2-10 million over the first two years [44].
For context, that is roughly what KPMG was paid just to promote adoption of the Palantir platform that two-thirds of trusts declined to use.
The returns are not speculative. A Forrester Total Economic Impact study of Stardog found 320% ROI over three years, with GBP 7.8 million in total benefits for a composite organisation. A separate Forrester study of Neo4j found 417%. Data scientist productivity improved 75-95%. Analytics development accelerated 2-3x. A separate study by Strategy Mosaic found 551% ROI with a two-month payback period [14b][45]. Infrastructure costs typically fall 30-70% because the virtual layer eliminates the duplication and storage overhead that traditional data warehouses demand. Time-to-insight drops by 85%. Language model accuracy on complex relational queries improves threefold [13].
The training investment - GBP 50,000-200,000 to teach domain experts graph literacy and ontology design - is the part that pays for itself most reliably and most permanently. Because unlike a consulting engagement, the skills stay in the building when the training is over. One FTE can maintain 50-100 entity types. Three to ten trained domain experts can run the semantic layer for an entire enterprise. The ongoing "ontology tax" that consultants warn about - the $10-20 million long-term maintenance figure for large graphs - applies only when nobody internal understands the graph. When your own underwriters and clinicians built it, maintenance is just part of their job [44].
The recommended path: start virtual, start small, mandate capability transfer in any vendor work, measure accuracy and P&L impact from day one. Payback typically arrives in six to twelve months.
That is how the 5% started. Not with a revolution. With a map that preserved what the spreadsheets threw away.
But here is the part that the top-down planners always miss. Ontologies do not spread like a shepherd imposing order on a flock. They spread like a virus.
Samuel Slater memorised the blueprints of Richard Arkwright's textile mill and carried them in his head across the Atlantic. No government programme commissioned it. No central authority approved the transfer. One person understood the shape of the machine, and the Industrial Revolution went viral in a new continent. Graph literacy spreads the same way. One claims handler learns to draw the connections between her systems. She shows a colleague. The colleague shows the next team. Within months, the map in the dirt has spread across departments - not because anyone mandated it, but because it works. The people closest to the problem can see the shape immediately. They have been carrying it in their heads for years. All they needed was a language for it.
You do not need a GBP 330 million contract to start this. You need one team, one domain, one set of relationships drawn in the dirt. The virus does the rest.
9.1 Five Who Chose the Virus
Regeneron Pharmaceuticals built a 16-week, role-based data literacy programme for its own staff instead of hiring external consultants. They upskilled 450 employees. Data literacy knowledge rose 21%. Awareness of their corporate data catalogue rose 40%. Their business analysts began standardising product comparison data independently. Their portfolio managers built their own resourcing models. The consultants were not fired. They were simply never needed again [39].
CRICO, the Harvard-affiliated malpractice insurer, embedded data literacy competencies into every corporate job description. Not a training day. Not a workshop. A structural change to what "working here" means. Within three years, employees across underwriting, claims, and clinical risk management were independently analysing complex data dashboards and streamlining clinical data collection across external hospitals - without a single consultant in the room [40].
AstraZeneca solved the gap between graph-literate specialists and their existing SQL-trained workforce with an elegant bridge: a small internal team curated the core business ontologies, then exposed them as standard tables so that 95% of regular IT staff could query them without learning a graph language. Complex cohort searches dropped from weeks to minutes. The external data curators who had been doing this work were displaced not by AI, but by the company's own people using their own ontology [41].
Swatch Group's lead architect initiated a "data-first" overhaul of their Configuration Management Database using a unified enterprise ontology built in-house. They bypassed external systems integrators entirely. The architecture simplified. The budget overruns that plague consultant-led IT projects simply did not materialise [42].
A government agency tasked with detecting suspicious behaviour chose not to deploy a static, outsourced tool. Instead, they trained their own subject-matter experts in knowledge graph design and graph machine learning. Those internal staff then wrote and ran their own detection algorithms, uncovering patterns that no external vendor's off-the-shelf product had found. The vendor dependency never formed in the first place [43].
Five organisations. Five industries. Same pattern. Invest the budget in your own people. Teach them the shape. The virus spreads. The consultants go home.
As Articul8 AI put it: "To make GenAI useful at enterprise scale, we must stop training intelligence on tabular noise" [31].
10. The Five Percent Manifesto
The era of the GBP 330 million band-aid is over.
For decades, the Great SQL Monoculture has kept our enterprise data tied up like obstinate goats in a paddock, facing different directions and resolutely refusing to mingle. And for decades, the insurance industry and the NHS have paid a staggering premium to external consultants just to tell us what those isolated goats are thinking.
But the 5% of companies that are actually succeeding with AI - the Lemonades, the Roots, the forward-thinking institutions - have cracked the code. They are not buying better algorithms or more expensive black boxes. They are building better environments. They are tearing down the fences, unclipping the carabiners, and letting their data connect in rich, semantic graphs.
Most importantly, they are handing the keys back to their own people.
Artificial intelligence is not a software subscription you can rent from an external vendor; it is a structural capability you must cultivate from within. When you teach your underwriters, your clinicians, and your claims handlers the true shape of the data, the magic returns in-house. You no longer need to outsource your corporate memory. The AI becomes explainable, and treating people like people becomes a natural byproduct of your architecture. Consumer Duty - being fair. Customer Care - making people feel listened to. Duty of Care - the whole-person responsibility the NHS carries every day. These are not compliance checkboxes; they are what connected data does automatically when the relationships are intact. And the multi-million-pound consulting dependency simply evaporates.
The 95% will keep writing blank cheques to external vendors and wondering why their pilots continuously fail to reach production.
The 5% will connect their data, empower their staff, and own their intelligence.
The 5% are not smarter. They are not better funded. They simply noticed, at some point, that the world is made of relationships, and built their systems to remember that. The other 95% are still extracting it into rows, one cell at a time, and wondering why the model cannot tell them anything they did not already know.
Follow the Five Percent.
References
[1] Estrada, S. (2025). MIT report: 95% of generative AI pilots at companies are failing. Fortune.
[2] RAND Corporation. (2024). An Assessment of Artificial Intelligence Projects in the Department of Defense. RAND Research Reports.
[3] QuickLaunch Analytics. (2025). Why 80% of AI Projects Fail Before They Start: It's Your Data Foundation.
[4] Cooper, P. (2026). Fable: The Shape of Thought - A Measurement Problem in Knowledge Representation. Zenodo. DOI: 10.5281/zenodo.19826509
[5] Codd, E. F. (1970). A Relational Model of Data for Large Shared Data Banks. Communications of the ACM, 13(6), 377-387.
[6] Cooper, P. (2026). The Shape of Thought: The Cognitive Architecture of Intelligence Failure. Working paper.
[7] Scott, J. C. (1998). Seeing Like a State: How Certain Schemes to Improve the Human Condition Have Failed. Yale University Press.
[8] Robinson, I., Webber, J., & Eifrem, E. (2015). Graph Databases: New Opportunities for Connected Data. O'Reilly Media.
[9] Hochmann, J. R., Carey, S., & Mehler, J. (2018). Infants learn a rule predicated on the relation same but fail to simultaneously learn a rule predicated on the relation different. Cognition, 177, 49-57.
[10] Dunbar, R. I. M. (1998). The social brain hypothesis. Evolutionary Anthropology, 6(5), 178-190.
[11] Meadows, D. H. (2008). Thinking in Systems: A Primer. Chelsea Green Publishing.
[12] Li, S. et al. (2025). BIRD-Bench / Spider 2.0: Text-to-SQL accuracy under schema complexity. See also arXiv:2506.05690v3 for graph-vs-tabular RAG analysis.
[13] Medium / ZS Associates. (2025). Meaning and Metadata: Why Semantic Layers Are Key to Generative AI Success.
[14] Microsoft Research. (2024). GraphRAG: Unlocking LLM Discovery on Narrative Private Data.
[14b] Forrester Research. (2024). The Total Economic Impact of Enterprise Knowledge Graph Platforms. Commissioned study (Stardog): 320% ROI. Also: Forrester (2023). The Total Economic Impact of Neo4j Graph Database: 417% ROI.
[15] NAM Info Inc. (2025). Why AI Projects Fail: The Cream of Engineers Don't Understand Data.
[16] SqlDBM. (2025). Why AI Projects Fail Without Data Modeling.
[17] Nisbett, R. E. (2003). The Geography of Thought: How Asians and Westerners Think Differently... and Why. Free Press.
[18] Tetlock, P. E. (2005). Expert Political Judgment: How Good Is It? How Can We Know? Princeton University Press.
[19] Insurance Technology Landscape - UK & European Market. (2026). AgileMesh Research.
[20] Lemonade Inc. (2025). Annual Report (10-K). Filed with SEC.
[21] Root Inc. (2025). Annual Report (10-K). Filed with SEC.
[22] Shift Technology. (2025). Shift Technology Launches Shift Claims to Power Claims Transformation with Agentic AI. Press release.
[23] Allianz. (2025). When the Storm Clears, So Should the Claim Queue. Press release.
[24] McKinsey & Company. (2025). Insurance 2030: The Impact of AI on the Future of Insurance.
[25] AI in Insurance Market Size, Share & Trends Analysis Reports, 2025-2035. Range $175-303B reflects Precedence Research ($176.58B), InsightAce ($303.31B), and Market.us estimates.
[26] Deloitte. (2024). The Future of Insurance Fraud Analytics.
[27] Financial Crisis Inquiry Commission. (2011). The Financial Crisis Inquiry Report. US Government Publishing Office.
[28] Various. Drug interaction knowledge graph literature. See Cooper (2026) [6] for full review.
[29] National Commission on Terrorist Attacks Upon the United States. (2004). The 9/11 Commission Report.
[30] Endo, A., et al. (2020). Estimating the overdispersion in COVID-19 transmission using outbreak sizes outside China. Wellcome Open Research, 5, 67.
[31] Articul8 AI. (2025). Why Gen AI Projects Fail and What It Takes to Rethink Enterprise Data Architecture. Blog post.
[34] NHS England / DHSC. (2023). Palantir awarded GBP 330 million Federated Data Platform contract. Multiple sources including: openDemocracy investigation (2024), British Medical Journal coverage, NHS Digital transparency reports.
[35] openDemocracy. (2024). Investigation: The True Cost of NHS Palantir. Also: BMJ (2024) coverage of KPMG adoption promotion fees (GBP 8-8.5m); NHS trust integration cost data from parliamentary questions and FOI responses. Trust adoption rates from NHS Digital transparency reports (mid-2025).
[36] Multiple sources on AI consulting lock-in: Gartner (2024), Harvard Business Review analysis of vendor dependency cycles, BCG consulting transformation failure rates. Global GenAI consulting spend figure from IDC (2025).
[37] BCG. (2024). The 10/20/70 Framework: Why AI Success Is 70% People and Processes. BCG Henderson Institute.
[38] FCA. (2025). Annual Enforcement Report. Fine totals and data governance citation analysis. Also: EU AI Act, Article 15 - accuracy, robustness, and cybersecurity requirements for high-risk AI systems. Regulation (EU) 2024/1689.
[39] Regeneron Pharmaceuticals. (2024). Internal data literacy programme case study. 16-week role-based programme, 450+ employees upskilled, 21% knowledge increase, 40% data catalogue awareness increase.
[40] CRICO / Risk Management Foundation of Harvard Medical Institutions. (2024). Data literacy integration across corporate job descriptions. Three-year programme embedding competencies into underwriting, claims, and clinical risk management roles.
[41] AstraZeneca. (2024). Internal ontology curation and SQL-accessible semantic layer for clinical data. Small specialist team curating business ontologies exposed as standard tables for existing workforce.
[42] Swatch Group. (2024). Enterprise ontology approach to CMDB overhaul. Internal data-first architecture bypassing external systems integrators.
[43] Government agency fraud detection case study. (2024). Internal knowledge graph and graph ML training for subject-matter experts, displacing outsourced static tooling.
[44] Semantic layer implementation cost benchmarks (2026). Composite estimates from Gartner, Forrester, and vendor case studies (Stardog, Ontotext, Neo4j, PoolParty). Pilot GBP 200-400k, mid-enterprise GBP 500k-2M, large-scale GBP 2-10M. Training GBP 50-200k. Maintenance: ~1 FTE per 50-100 entity types.
[45] Strategy Mosaic. (2024). Semantic Layer ROI Analysis. 551% ROI, 2-month payback, ~$3.4M net gain per studied customer, $279k/month value. Significant warehouse cost avoidance.
Citation: Cooper, P. (2026). Follow the Five Percent: What Graph-Literate Enterprises Did Differently and Why It Matters. Zenodo. DOI: 10.5281/zenodo.20423950
Licence: Creative Commons Attribution 4.0 International (CC BY 4.0)
Companion Works:
Cooper, P. (2026). Fable: The Shape of Thought - A Measurement Problem in Knowledge Representation. Zenodo. DOI: 10.5281/zenodo.19826509. Available at: theshapeofthought.com
Cooper, P. (2026). The Tabular Prison: The Financial Cost of Graph-Blindness in Enterprise Intelligence. Zenodo. DOI: 10.5281/zenodo.20326278. Same evidence, different projection - diagnosis where this paper leads with winners.